Hi, I'm Aidul
Software Developer
Looking forward to working in such an environment that would allow me to use my conceptual, technical, analytical skills and abilities which offer professional growth while being resourceful, innovative, and dynamic.
Contact MeAbout Me
My Introduction
Myself Md. Aidul Islam. I've pursued my Bachelor of Science (Engg.) degree in CSE from IIUC, Bangladesh. Currently pursuing my masters in Computing Science and Software at Tampere University, Finland. Problem solving with many kinds of algorithms is an interesting topic for me. I like work with team too. I have many projects which was I, developed working with team members. I make android and web applications.
experience
project
worked in
Skills
My Technical LevelLanguages
Programming/Markup LanguagesPython
80%C++
70%Java
80%JavaScript
80%TypeScript
60%Kotlin
50%HTML5
80%CSS3
80%Operating System
Both PC & mobileDatabase
Database ManagementFrameworks
Both Frontend and BackendIDEs
Development ToolsVSC
Version Control SystemCareer
My Career journeyM.Sc in Software, Web & Cloud, Computing Sciences
Tampere UniversityB.Sc in Computer Science & Engineering
International Islamic University ChittagongHigher Secondary School Certificate (Science)
Government City College ChittagongSecondary School Certificate (Science)
Government Muslim High School ChittagongResearch Assistant
GPT-Lab, Tampere UniversitySoftware Engineer (Part-Time)
nztripAndroid Developer
Xit BangladeshAndroid Developer Intern
BroTech ITCertification
Awards, Achievements and Certifications
Full Stack Development
AI Cloud Academy
Certificate of CP Intermediate Level
DevSkill
Master Git and GitHub
Udemy
Projects
Most Recent Work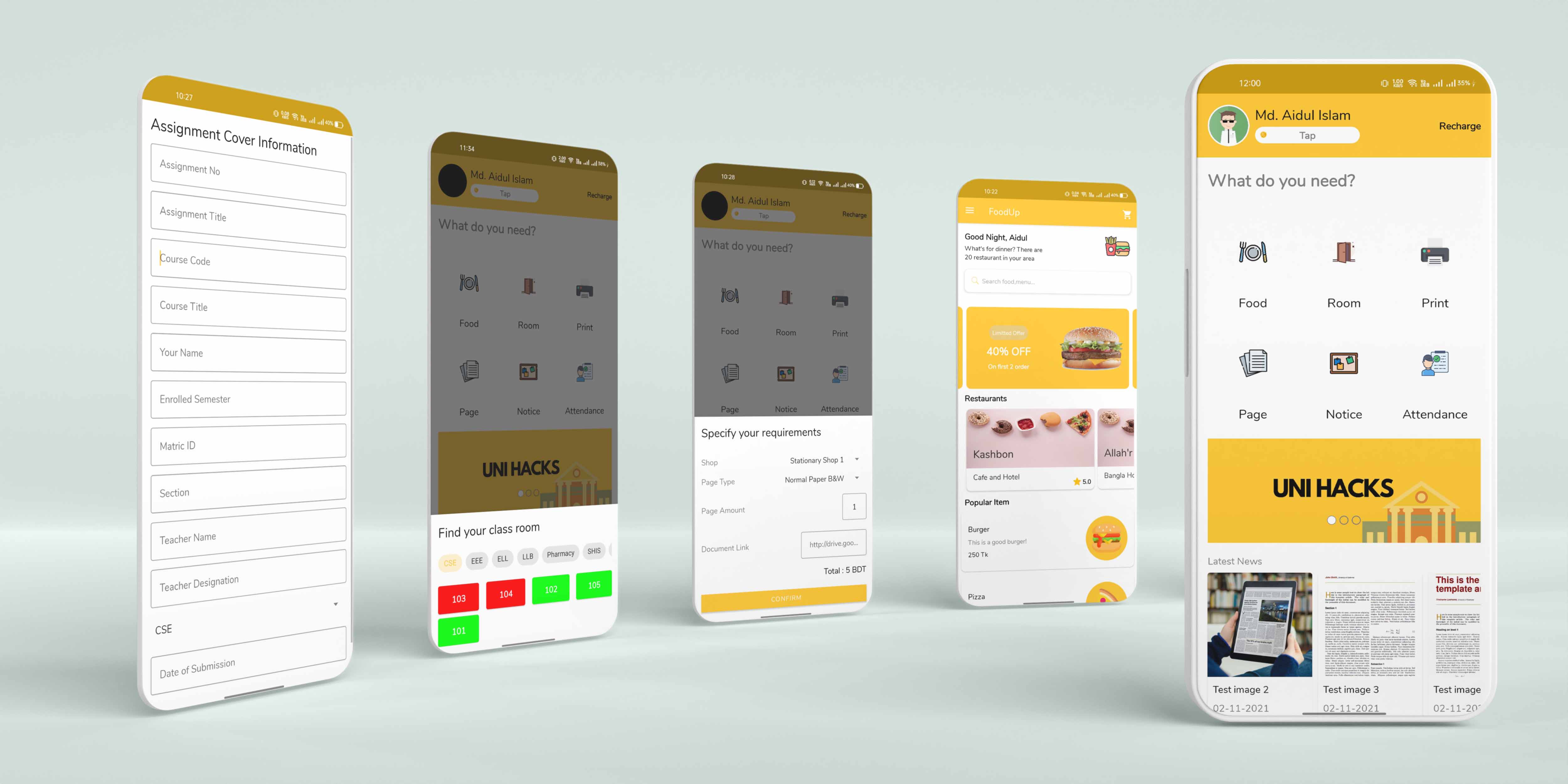
UNI HACKS - Smartphone Based University Utility App
The project is entitled as “UNI HACKS". This eas the final project of my bachelor in CSE. Me and my teammate try to solve those problems, which an university student face on the campus.
Demo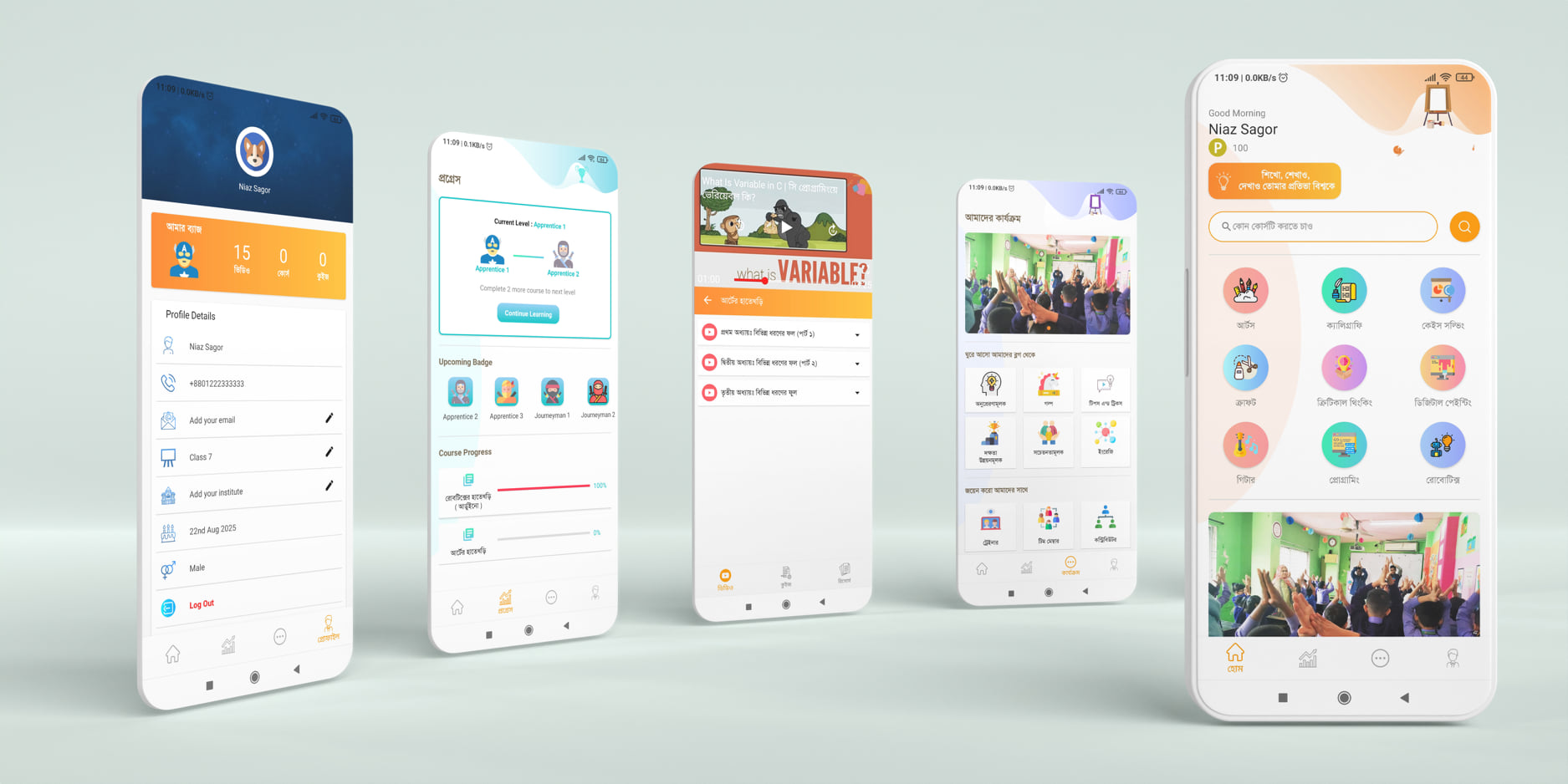
eDU - Interactive e-Learning Application
This is an interactive e-learning app for childern. Me and one of my friend made this application for an organaization called Ofk-Opportunity for Kids.
Demo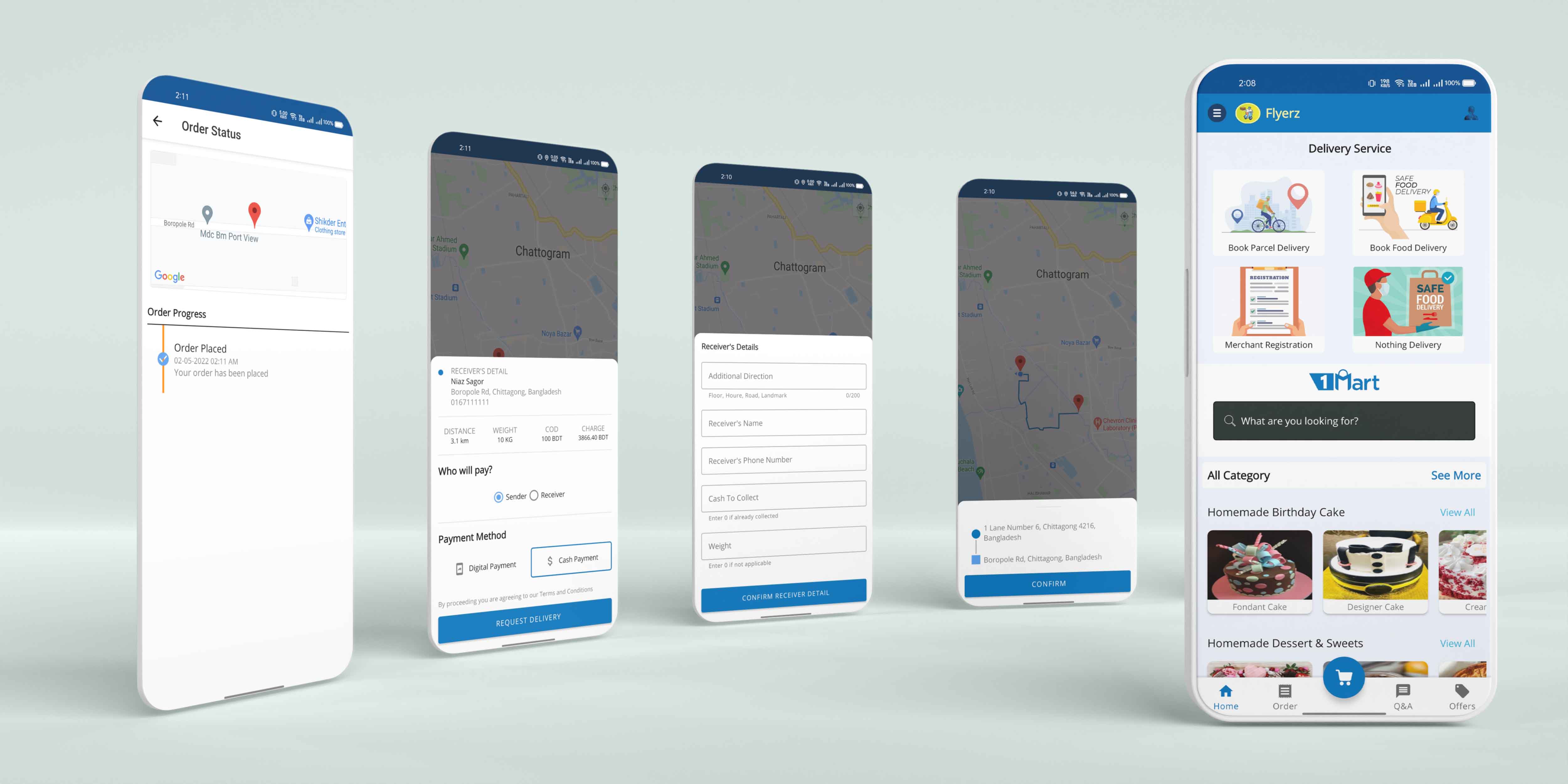
Flyerz - Multi Vendor eCommerce App
This is a multi vendor eCommerce application. I work on this project while I was doing my intership. I work on the delivery section of this application where I implement Google Map services and other api and third party libraries.
Demo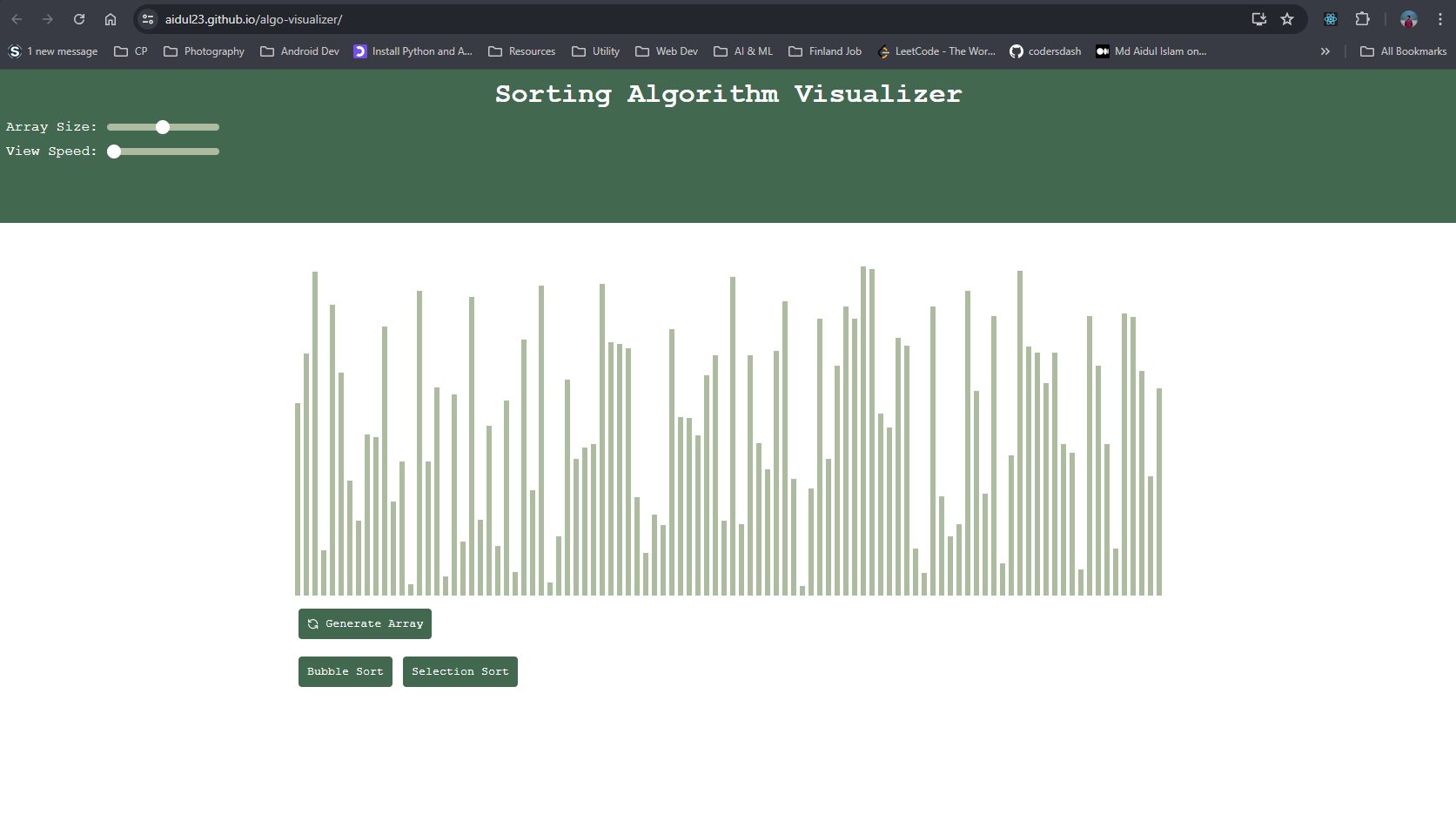
Algorithm Visualizer
A simple sorting algorithm visualizer using javascript React library, where you can generate random number with size, set the speed of the execution for better visual.
Demo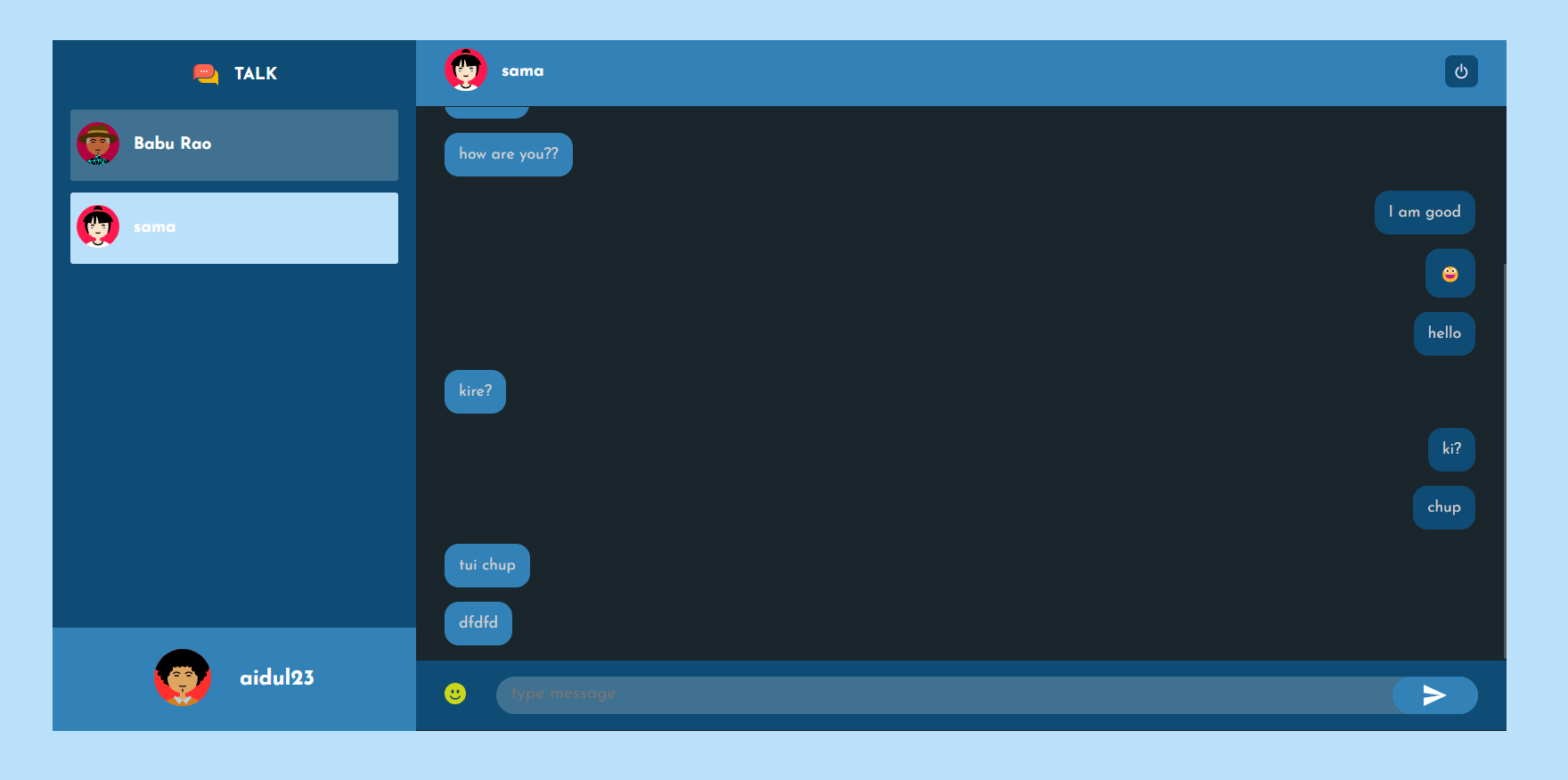
Talk
This is a real-time chat application using a web socket where one can create an account, set an avatar, and chat with another person.
Demo
Testimonial
My acquaintances are saying
Niaz Sagor
TeammateMy university classmate and very good friend. We did several courses together and some amazing project also. Just an amazing person, a very quick learner, can learn a new tech within a very short time.

Rahul Sikdar
FriendYou are friendly and helpful. You are good at coding structure, a very quick learner, can learn a new tech within a very short time.

Robiul Alam
ColleagueAidul worked with me more than a year. He is so pationate about his work. I specially like his enthusiasm about learning new technology.

Khadiza Morioum
FriendHis work is really amazing. I have given him a project. He completed it Perfectly. Also didn't exceeded the the deadline.